NLP (Traitement du Langage) : le “vrai début” de l’IA… avant le boom de l’IA générative
Aujourd’hui, beaucoup découvrent l’IA par ChatGPT, les images, les vidéos, etc. Mais sous le capot, une grande partie de l’IA “utile” a commencé par un truc très simple à dire… et très dur à faire :
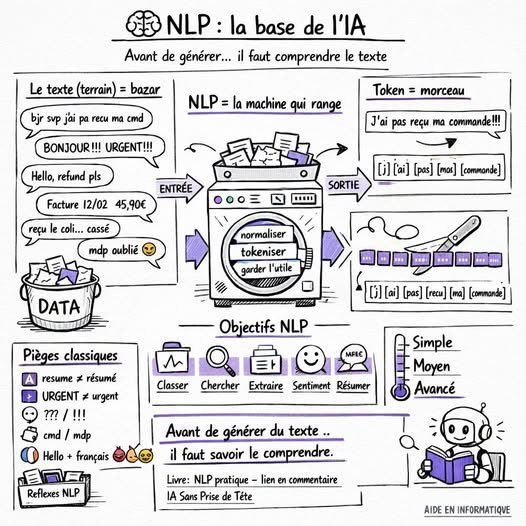
NLP (Traitement du Langage) : le “vrai début” de l’IA… avant le boom de l’IA générative
Aujourd’hui, beaucoup découvrent l’IA par ChatGPT, les images, les vidéos, etc.
Mais sous le capot, une grande partie de l’IA “utile” a commencé par un truc très simple à dire… et très dur à faire :
comprendre du texte humain.
Parce que dans la vraie vie, tout est du texte :
emails, tickets support, WhatsApp, commentaires Facebook, CV, contrats, factures, rapports, messages clients, avis Google…
Si ta machine ne sait pas lire et interpréter ce texte…
elle ne peut pas classer, chercher, résumer, détecter une fraude, analyser un sentiment, faire un chatbot, etc.
C’est quoi exactement le NLP ?
Le NLP (Natural Language Processing), c’est l’ensemble des techniques qui permettent à une machine de :
nettoyer du texte (sans casser le sens)
comprendre le vocabulaire (mêmes mots écrits différemment)
transformer du texte en données exploitables (features)
apprendre à reconnaître des patterns (spam, urgence, thème, intention…)
retrouver des infos (recherche intelligente, similarité)
extraire des champs (date, montant, nom, référence…)
résumer (simple ou avancé)
et bien sûr… préparer le terrain pour les modèles modernes (Transformers, LLM, etc.)
Analogie terre-à-terre :
Le NLP, c’est comme apprendre à un enfant à lire des messages de gens différents.
Certains écrivent propre, d’autres en SMS, d’autres en MAJUSCULE, d’autres mélangent français/anglais, d’autres mettent des emojis …
Ton job, c’est de lui apprendre à comprendre malgré tout.
✅ Les objectifs “terrain” du NLP (ce qu’on fait en entreprise)
1) Classification
Spam / pas spam
Urgent / normal
Réclamation / remboursement / livraison / bug
Message toxique / neutre
2) Recherche & Similarité
Tu tapes “remboursement” et tu veux aussi trouver “refund”, “annuler commande”, “je veux être remboursé”.
3) Extraction d’informations
Dans “Facture 12/02 montant 45,90€” → extraire date + montant + parfois référence.
4) Analyse de sentiment
Comprendre si le client est content , neutre , ou énervé .
5) Résumé
Résumer un long mail / rapport / conversation.
6) Pré-traitement pour l’IA moderne
Même les LLM ont besoin de texte propre, données cohérentes, formats bien préparés.
----------------------------------------------------
Extrait de notre livre (copié/collé)
NLP pratique — Comprendre et traiter du texte (sans Transformer d’abord)
Du texte brut à des modèles utiles : nettoyage, features, classification, résumé simple.
-----------------------------------
Chapitre 1 — Le texte, c’est sale : accents, fautes, tokens (réalité)
Si tu viens du machine learning “tabulaire” (colonnes numériques propres), le texte va te surprendre.
Parce que le texte, ce n’est pas une colonne age=32 ou prix=19.99.
Le texte, c’est de l’humain. Donc c’est… sale
Et “sale” ici ne veut pas dire mauvais.
Ça veut dire : incohérent, imprévisible, plein d’exceptions.
L’objectif de ce chapitre est simple :
✅ te montrer pourquoi le texte est difficile,
✅ et te donner les bons réflexes dès le départ, avant de parler de TF-IDF, de modèles, etc.
1.1 Le texte, c’est le bazar du monde réel
Imagine un fichier emails.csv avec une colonne message.
Tu t’attends à des phrases propres.
Mais tu reçois plutôt :
“bjr svp j’ai pa recu ma cmd”
“Bonjour, je n’ai pas reçu ma commande ”
“BONJOUR!!! URGENT!!!!”
“reçu le coli… mais cassé”
“Bonjour, facture 12/02 montant 45,90€”
“hello, i want refund pls”
“J’ai oublié mon mdp !!!”
Ça parle du même sujet… mais écrit de 10 manières.
Donc première vérité :
le texte est une donnée non standardisée.
1.2 Les problèmes “classiques” du texte (terrain)
Voici ce qui casse souvent un projet NLP si tu ne le vois pas venir.
A) Accents & variantes
“resume” vs “résumé”
“cote” vs “côté”
“a” vs “à”
En informatique, ce sont des chaînes différentes.
Donc si tu “comptes les mots”, tu comptes deux mots différents.
B) Casse (MAJ/min)
“URGENT” vs “urgent”
“PayPal” vs “paypal”
Si tu ne normalises pas, ton modèle croit que ce sont des mots différents.
C) Ponctuation / symboles
“commande!!!”
“commande…”
“commande??”
“commande :)”
“45,90€” vs “45.90 EUR”
La ponctuation peut être du bruit… ou une info (ex: “???” peut signaler un client énervé).
D) Fautes, abréviations, langage SMS
“svp”, “stp”
“cmd” (commande)
“rdv” (rendez-vous)
“pb”, “probleme”, “problème”
“j’ai pa”, “j’ai pas”
Le même concept peut apparaître sous plusieurs formes.
E) Mélange de langues
Tu peux avoir du français + anglais dans la même phrase :
“Hello, je veux refund svp”.
F) Emojis
✅
Ils peuvent être du bruit… ou un signal très fort (sentiment, urgence).
G) Doublons / texte copié-collé
Certains messages sont quasi identiques (templates).
Ça biaise les stats et l’apprentissage.
1.3 Token : c’est quoi au juste ?
Avant de modéliser, on doit “couper” le texte en morceaux.
Ces morceaux, on les appelle des tokens.
Tokenisation simple : couper par espaces et ponctuation.
Tokenisation plus fine : gérer apostrophes, chiffres, etc.
Exemple :
Phrase :
"J’ai pas reçu ma commande!!!"
Tokens naïfs :
["J’ai", "pas", "reçu", "ma", "commande!!!"]
Tokens propres :
["j", "ai", "pas", "recu", "ma", "commande"]
On voit déjà le problème :
si tu tokenises mal, tu fabriques des “mots” bizarres (“commande!!!”) qui polluent ton vocabulaire.
1.4 Le piège numéro 1 : croire que “nettoyer” veut dire “détruire”
Quand on débute, on fait souvent ceci :
on enlève tout
on supprime les chiffres
on supprime la ponctuation
on supprime les accents
on supprime les mots courts
on supprime les stopwords
Et au final… on perd des infos utiles.
Exemple :
“Facture 12/02 montant 45,90€”
Si tu supprimes chiffres et ponctuation :
→ “facture montant”
Tu as perdu la date et le montant, alors que c’était l’info principale.
Donc règle d’or :
✅ On nettoie pour simplifier, pas pour effacer.
✅ Tout dépend du but (classification ? extraction ? recherche ?).
1.5 Mini-exemples concrets : pourquoi ça compte
Cas 1 : classification “spam vs pas spam”
“GAGNE 1000€” → spam
“urgent facture 1000€” → pas spam
Ici, le mot “1000€” n’est pas forcément spam.
Le contexte change tout.
Cas 2 : recherche “retrouver un doc”
Tu veux retrouver des emails parlant de remboursement.
Tu tapes : “remboursement”
Mais les clients écrivent :
“refund”
“rembourser”
“RMB” (rare)
“je veux être remboursé”
“annuler commande”
Donc tu as besoin de techniques de similarité (chapitre 5).
Cas 3 : extraction d’infos
Tu veux extraire un montant et une date.
Tu dois conserver chiffres et formats.
Donc ton nettoyage sera différent de celui d’un spam classifier.
1.6 Les bons réflexes “NLP terrain” dès maintenant
Avant même TF-IDF, retiens ces réflexes :
Toujours regarder des exemples réels (50–200 lignes)
Définir le but : classer ? chercher ? extraire ? résumer ?
Décider quoi garder (chiffres, emojis, ponctuation)
Tokeniser proprement (sinon vocabulaire pourri)
Faire un baseline simple avant les modèles “lourds”
-----------------------------------------------------------
Conclusion terre à terre (à retenir)
Le NLP, c’est la base :
Avant de “générer” du texte… il faut savoir lire le texte.
Avant de faire de l’IA “wahou”… il faut faire de l’IA utile sur les vrais messages du terrain.
Et souvent, un bon TF-IDF + modèle simple bien nettoyé bat un gros modèle mal préparé
Le lien du livre est en commentaire
Ce livre fait partie de la collection : “IA Sans Prise de Tête — La Collection Pratique”.
Si tu veux, dis-moi en commentaire :
tu veux qu’on fasse le prochain post sur TF-IDF expliqué ultra simple, ou sur “comment transformer du texte en chiffres” ?
Rejoins nos canaux pour être alerté de tous nos posts et contenus.
Tous les liens utiles sont en commentaire.
Quelle est votre réaction?