Coder un réseau de neurones à la main (sans bibliothèques)
Comprendre ce qui se passe vraiment sous le capot de l’IA Quand on débute en intelligence artificielle, une question revient très souvent : « D’accord… mais ils font comment, concrètement ? » On utilise TensorFlow, PyTorch, Keras, scikit-learn…
Comprendre ce qui se passe vraiment sous le capot de l’IA
Quand on débute en intelligence artificielle, une question revient très souvent :
« D’accord… mais ils font comment, concrètement ? »
On utilise TensorFlow, PyTorch, Keras, scikit-learn…
Ça marche.
Les résultats sont impressionnants.
Mais au fond, beaucoup gardent un doute :
est-ce que je comprends vraiment ce que je fais ?
Dans cet article, on va volontairement enlever les bibliothèques et revenir aux bases :
coder un réseau de neurones à la main, pour comprendre ce qui se passe réellement sous le capot.
L’objectif n’est pas de concurrencer les frameworks industriels, mais de raisonner mieux, d’optimiser intelligemment, et d’utiliser l’IA en connaissance de cause.
Une analogie simple pour commencer
Imagine une calculatrice.
Tu peux :
-
soit appuyer sur les touches sans savoir comment elle calcule,
-
soit comprendre qu’à l’intérieur il y a des circuits, des additions, des multiplications, des registres.
Les bibliothèques IA, c’est pareil.
Elles sont comme des calculatrices très puissantes.
Comprendre un réseau de neurones « from scratch », c’est ouvrir la calculatrice et regarder dedans.
Une vérité que peu de gens disent
Un réseau de neurones, avant d’être de l’IA, c’est :
-
des nombres
-
des équations
-
des boucles
-
des structures de données
Rien de magique.
Comme :
-
une liste
-
un tableau
-
un arbre
-
un graphe
On n’implémente pas toujours ces structures à la main, mais on sait comment elles fonctionnent.
C’est exactement la même logique ici.
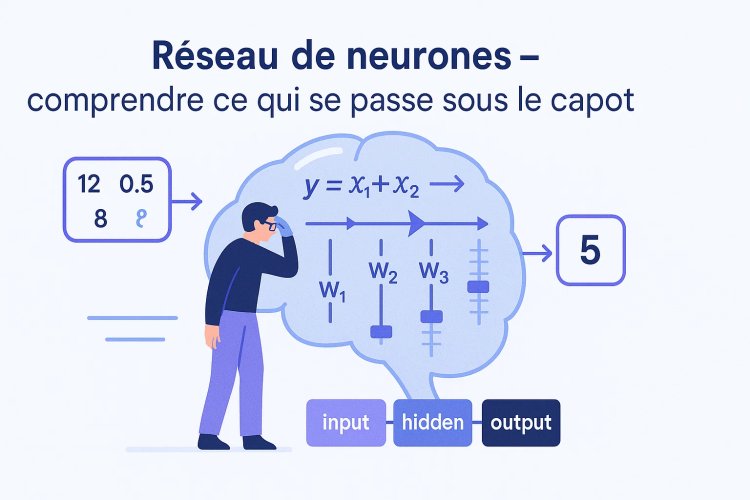
Un réseau de neurones, c’est quoi techniquement ?
D’un point de vue bas niveau, un réseau de neurones est :
-
un ensemble de neurones
-
organisés en couches
-
reliés par des poids
-
avec une fonction mathématique qui transforme les données
Chaque neurone fait une chose très simple :
Il prend des nombres, les multiplie par des poids, additionne, puis applique une fonction.
Rien de plus.
Les briques de base à coder
Si on enlève toutes les bibliothèques, on se retrouve avec seulement trois concepts à implémenter.
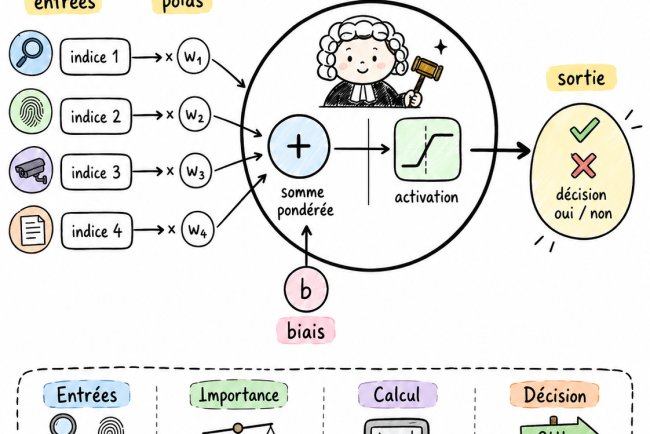
1. Le neurone
Un neurone contient :
-
une liste de poids
-
un biais
-
une fonction d’activation
Mathématiquement, il calcule :
sortie = activation( w1*x1 + w2*x2 + ... + wn*xn + biais )
C’est tout.
2. La couche (layer)
Une couche est simplement :
-
un groupe de neurones
-
qui reçoivent tous les mêmes entrées
-
et produisent plusieurs sorties
Comme une équipe d’ouvriers qui reçoivent le même plan mais travaillent chacun à leur poste.
3. Le réseau de neurones
Le réseau est :
-
une succession de couches
-
où la sortie d’une couche devient l’entrée de la suivante
Exactement comme une chaîne de montage.
Que signifie vraiment “entraîner” un réseau ?
C’est ici que beaucoup de mystères apparaissent.
En réalité, entraîner un réseau signifie simplement :
Trouver les bons nombres (les poids).
Rien de plus.
Étape 1 : le dataset
On fournit :
-
des entrées (x)
-
des sorties attendues (y)
Exemple :
-
entrée : température, humidité
-
sortie : allumer ou non un ventilateur
Étape 2 : initialisation des poids
Au début, les poids sont mauvais.
On les initialise souvent au hasard.
Comme un cuisinier qui teste une recette sans encore connaître les bonnes proportions.
Étape 3 : propagation avant (forward propagation)
On fait passer les données dans le réseau.
On obtient une prédiction.
Souvent fausse au début.
Étape 4 : calcul de l’erreur
On compare :
-
ce que la machine a prédit
-
ce qu’elle aurait dû prédire
La différence, c’est l’erreur.
Étape 5 : apprentissage (backpropagation)
On utilise les mathématiques (dérivées, gradients) pour répondre à une seule question :
Dans quel sens faut-il ajuster les poids pour réduire l’erreur ?
On corrige un peu.
Puis on recommence.
Encore.
Encore.
Encore.
C’est exactement comme apprendre à lancer une balle dans un panier.
Pourquoi coder tout ça à la main ?
Parce que comprendre le bas niveau change tout.
Quand tu comprends :
-
pourquoi un modèle sur-apprend
-
pourquoi il sous-apprend
-
pourquoi il consomme trop de ressources
-
pourquoi un paramètre change tout
Tu n’utilises plus l’IA comme une boîte noire.
Tu raisonnes.
Impact concret pour un développeur ou un ingénieur
Comprendre un réseau de neurones “from scratch” permet de :
-
mieux choisir une architecture
-
mieux dimensionner un modèle
-
éviter le gaspillage de ressources
-
comprendre les limites d’un modèle
-
dialoguer intelligemment avec les data scientists
-
ne pas croire que l’IA est magique
Et surtout :
ne plus avoir ce doute permanent : “je l’utilise, mais je ne sais pas vraiment comment”
En pratique
Un petit réseau de neurones codé à la main peut tenir en quelques fichiers :
-
Neuron
-
Layer
-
NeuralNetwork
Que ce soit en C, C++, C#, Java, Python ou autre, les concepts restent identiques.
Seule la syntaxe change.
Conclusion
Les frameworks modernes sont indispensables.
Mais comprendre ce qui se passe en dessous est une arme.
Plus tu comprends le bas niveau, plus tu deviens efficace au haut niveau.
C’est vrai pour :
-
les systèmes d’exploitation
-
les réseaux
-
le cloud
-
et aujourd’hui, l’intelligence artificielle
L’IA n’est pas magique.
Elle est mathématique, logique, déterministe.
Et ça, c’est une excellente nouvelle pour ceux qui veulent vraiment la maîtriser.
Si ce type de contenu te parle, Aide en Informatique publie régulièrement des articles et ressources pour comprendre l’informatique moderne sans jargon inutile, en expliquant ce qui se passe réellement sous le capot.
un exemple concret de code en c# se trouve sur notre github ici
https://github.com/Defcoq/NeuralNetwork
n'oubliez pas de visitez notre catalogue Amazon des livres sur la IA ici
Quelle est votre réaction?