Étude de la tolérance aux pannes dans les architectures Cloud natives
Analyse de la résilience et de la haute disponibilité Les applications “cloud natives” sont souvent présentées comme toujours disponibles. Dans l’imaginaire collectif, le Cloud serait une sorte de machine parfaite : scalable, robuste, et sans interruption.
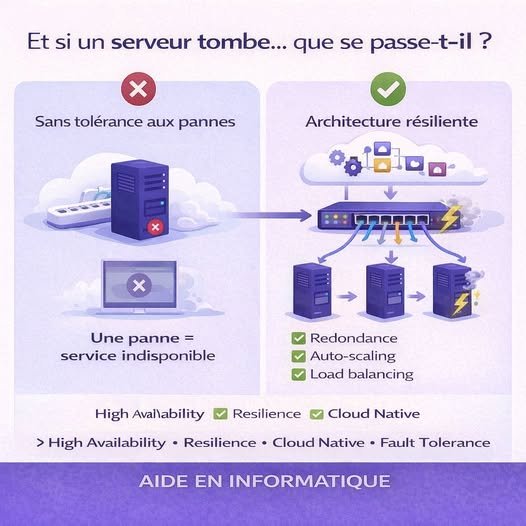
Étude de la tolérance aux pannes dans les architectures Cloud natives
Analyse de la résilience et de la haute disponibilité
Les applications “cloud natives” sont souvent présentées comme toujours disponibles. Dans l’imaginaire collectif, le Cloud serait une sorte de machine parfaite : scalable, robuste, et sans interruption.
Dans la réalité, c’est beaucoup plus nuancé :
-
des serveurs tombent
-
des conteneurs meurent
-
des zones cloud peuvent devenir indisponibles
-
le réseau peut se dégrader
-
un service dépendant peut ralentir ou tomber
La vraie question (et un excellent sujet de thèse) est donc :
Comment concevoir une architecture Cloud capable de continuer à fonctionner malgré les pannes ?
C’est tout l’enjeu de la tolérance aux pannes, de la résilience et de la haute disponibilité.
Pourquoi c’est un excellent sujet de thèse
Ce sujet est particulièrement intéressant parce qu’il colle à la réalité des entreprises :
-
très demandé (Cloud, microservices, DevOps, SRE)
-
au cœur des architectures modernes
-
applicable en licence, master, ou formation professionnelle
-
mélange théorie et pratique avec des cas concrets
-
différenciant sur un CV (architecte, DevOps, SRE, ingénieur plateforme)
Ce n’est pas une thèse “théorique” : c’est un sujet terrain, où l’on peut produire des livrables exploitables.
Comment aborder la thèse, étape par étape
1) Bases théoriques
Commencer par clarifier les notions essentielles :
-
qu’est-ce qu’une panne (et quels types de pannes existent)
-
disponibilité, résilience, tolérance aux pannes : différences réelles
-
notions de SLA / SLO / SLI (indicateurs et objectifs de fiabilité)
2) Comprendre une architecture Cloud native
Poser le cadre technique :
-
microservices et dépendances
-
stateless vs stateful (et pourquoi c’est critique pour la résilience)
-
conteneurs et orchestration
-
multi-zone et multi-région (et ce que ça implique en coûts et complexité)
3) Étudier les mécanismes de résilience
Analyser les briques qui permettent de survivre aux incidents :
-
load balancing
-
auto-scaling
-
redondance
-
health checks
-
retry / timeout (et les risques si mal configurés)
-
circuit breaker (éviter l’effet domino)
4) Mise en pratique (lab ou projet)
Construire une application “réaliste” et l’exposer à de vrais scénarios de panne :
-
déployer une application cloud (API + frontend + base de données, par exemple)
-
simuler des pannes (réseau, service, nœud, zone, surcharge)
-
observer le comportement et l’expérience utilisateur
-
mesurer ce qui se passe réellement, pas ce qu’on croit
5) Analyse et résultats
Produire des résultats concrets et comparables :
-
temps de reprise (RTO)
-
perte de données ou d’événements (RPO)
-
perte de service, erreurs côté utilisateur
-
comparaison “avec mécanismes de résilience” vs “sans mécanismes”
-
recommandations et bonnes pratiques
Outils typiques à utiliser
Selon l’orientation de la thèse, on peut s’appuyer sur :
-
fournisseurs Cloud : AWS, Azure, GCP
-
conteneurs : Docker
-
orchestration : Kubernetes
-
load balancer et auto-scaling
-
chaos engineering (tests de panne contrôlés)
-
monitoring : Prometheus, Grafana
-
CI/CD : GitHub Actions, GitLab CI
L’idée n’est pas de tout utiliser, mais de choisir un stack cohérent et exploitable dans le temps.
Ressources et accompagnement
Pour démarrer :
-
le lien de notre collection de livres “spécial Cloud” est disponible dans la section ressources / en bas de page (selon l’organisation du blog)
Et pour ceux qui vont plus loin :
une collection dédiée aux sujets de thèse (Cloud, admin système/réseaux, cyber, IA, coding…) est en préparation, avec :
-
méthodologie
-
cas pratiques
-
architectures commentées
-
exemples concrets et livrables
L’esprit Aide en Informatique
Notre objectif reste le même : proposer des sujets utiles, et accompagner ceux qui les choisissent, pas à pas, du démarrage jusqu’à la soutenance.
Vous avez des questions, ou vous voulez des idées de lab Cloud réalistes (pannes à simuler, métriques à mesurer, architecture type) ?
On en parle en commentaire.
Quelle est votre réaction?