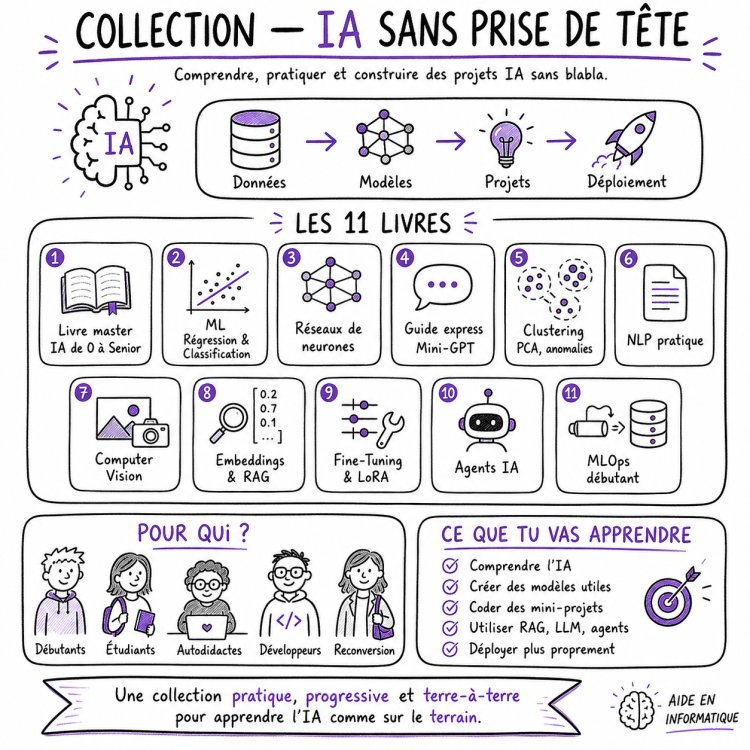
Collection — IA Sans Prise de Tête
La collection IA Sans Prise de Tête — La Collection Pratique a été conçue pour aider les débutants, les étudiants, les autodidactes, les développeurs, les personnes en reconversion et les curieux à apprendre l’intelligence artificielle de manière simple, progressive et concrète. Aujourd’hui, l’IA est partout : recommandations, chatbots, classification, recherche sémantique, analyse de texte, vision par ordinateur, assistants intelligents, agents, automatisation, modèles génératifs, déploiement de modèles et MLOps.
Collection — IA Sans Prise de Tête
cliquez ici pour acceder à la Collection — IA Sans Prise de Tête sur AMAZON
Collection : Les Maths Derrière L'IA (Série de 5 livres) sur AMAZON
La collection IA Sans Prise de Tête — La Collection Pratique a été conçue pour aider les débutants, les étudiants, les autodidactes, les développeurs, les personnes en reconversion et les curieux à apprendre l’intelligence artificielle de manière simple, progressive et concrète.
Aujourd’hui, l’IA est partout : recommandations, chatbots, classification, recherche sémantique, analyse de texte, vision par ordinateur, assistants intelligents, agents, automatisation, modèles génératifs, déploiement de modèles et MLOps.
Mais pour beaucoup de personnes, l’intelligence artificielle reste confuse.
On entend parler de machine learning, deep learning, réseaux de neurones, embeddings, Transformers, LLM, RAG, fine-tuning, LoRA, agents IA, MLOps… sans toujours comprendre ce que ces mots veulent dire, à quoi ils servent réellement, ni comment les utiliser dans des projets concrets.
Cette collection a été pensée pour changer cela.
L’objectif est simple : apprendre l’IA comme on la pratique, un thème à la fois, avec des analogies claires, des exemples Python, des mini-labs, des projets guidés et une pédagogie terre-à-terre.
Une collection pratique : un thème, un livre
La collection IA Sans Prise de Tête repose sur une idée simple : chaque volume traite un sujet précis.
Vous n’êtes pas obligé de tout lire dans l’ordre.
Vous pouvez commencer par le thème qui vous intéresse le plus : machine learning, réseaux de neurones, NLP, vision par ordinateur, RAG, fine-tuning, agents IA ou MLOps.
Chaque livre peut se lire seul, mais l’ensemble forme un parcours cohérent pour comprendre progressivement les grandes familles de l’intelligence artificielle moderne.
Le fil rouge reste toujours le même :
comprendre sans se noyer ;
pratiquer sans recopier aveuglément ;
construire des projets utiles ;
évaluer correctement ;
éviter les pièges classiques ;
passer du prototype au projet plus propre.
Ici, l’IA n’est pas présentée comme de la magie.
Elle est présentée comme une boîte à outils qu’on peut comprendre, tester, corriger et utiliser avec méthode.
Le livre master de la collection
La IA par des exemples pratiques de 0 à Senior
Ce livre est le pilier principal de la collection.
Il propose une vision complète de l’intelligence artificielle, depuis les bases jusqu’aux outils modernes : machine learning, deep learning, réseaux de neurones, IA générative, LLM, agents, RAG, projets Python et applications concrètes.
C’est le livre idéal pour ceux qui veulent avoir une trajectoire globale.
On y avance pas à pas, avec des analogies simples, des exemples pratiques et une progression qui permet de relier les grandes notions entre elles.
Le lecteur découvre l’histoire de l’IA, les outils Python, les bases du machine learning, les réseaux de neurones, les Transformers, les LLM, Hugging Face, Ollama, LangChain, LlamaIndex, ainsi qu’un projet final d’application IA.
L’objectif est de donner une vue d’ensemble solide avant de se spécialiser dans les volumes pratiques.
Les livres de la collection
Machine Learning — Régression & Classification
Ce volume apprend à construire des modèles utiles avec Python et Scikit-learn.
On y découvre quand utiliser le machine learning, comment préparer les données, comment faire de la régression pour prédire un nombre, comment faire de la classification pour ranger un cas dans une catégorie, et comment évaluer correctement un modèle.
Le lecteur apprend aussi les pièges classiques : mauvaise métrique, fuite de données, sur-apprentissage, jeu de test mal utilisé, modèle qui semble bon mais qui échoue dans la vraie vie.
L’objectif est de passer du “j’ai vu des tutos” à “je sais construire un pipeline propre et évaluer un modèle correctement”.
Réseaux de Neurones : De 0 à Pratique
Ce volume explique les réseaux de neurones sans les présenter comme une magie réservée aux chercheurs.
On y découvre ce qu’est un neurone artificiel, une fonction, un poids, une loss, une descente de gradient, puis on code progressivement des réseaux simples à la main avec Python et NumPy.
Ensuite, le lecteur passe à PyTorch et TensorFlow pour comprendre ce que les frameworks automatisent.
Le livre aborde aussi les CNN pour les images, les RNN et LSTM pour les séries temporelles, les Transformers pour le texte, et le lien avec les LLM.
L’objectif est de comprendre pourquoi un réseau apprend, comment l’entraîner, comment l’évaluer et comment éviter les erreurs classiques.
Maîtrisez l’IA — Le Guide Débutant Express
Ce volume est une porte d’entrée rapide pour comprendre l’intelligence artificielle moderne.
Il explique les grandes familles de l’IA, les bases mathématiques utiles, le fonctionnement des réseaux de neurones, les grands modèles de langage, et propose un projet pratique pour créer un mini-GPT pas à pas.
Il s’adresse à ceux qui veulent une première vision claire, directe et accessible, sans entrer immédiatement dans toute la profondeur technique.
L’objectif est de rendre l’IA compréhensible dès le départ, même pour ceux qui n’ont jamais construit de modèle.
Clustering & Réduction de dimension
Ce volume explique l’apprentissage non supervisé.
C’est le monde où l’on n’a pas de colonne “réponse”, pas de labels, pas de vérité toute faite.
Le lecteur apprend à chercher des groupes, des comportements, des structures cachées et des anomalies dans les données.
On y découvre le clustering, k-means, le choix du nombre de groupes, le clustering hiérarchique, DBSCAN, PCA, t-SNE, UMAP et la détection d’anomalies avec Isolation Forest.
L’objectif est de passer du chaos à des groupes plus clairs, sans se raconter d’histoires avec de mauvais graphiques ou des clusters artificiels.
NLP Pratique : Comprendre et traiter du texte
Ce volume apprend à travailler avec du texte réel.
Emails, tickets support, avis clients, messages, descriptions, documents : le texte est souvent sale, irrégulier, mélangé, rempli d’abréviations, de fautes, de ponctuation et de variations.
Le lecteur apprend à nettoyer, normaliser, transformer le texte en features, utiliser Bag-of-Words, TF-IDF, classifier des textes, rechercher des similarités, extraire des informations et produire un résumé simple.
L’objectif est d’apprendre le NLP utile avant de se jeter directement dans les Transformers.
On apprend à construire des outils concrets : trieur d’emails, classification de tickets, extraction de champs, recherche simple et sortie structurée.
Computer Vision : Reconnaître, détecter, classer
Ce volume explique comment une machine peut “voir” avec des images.
On y découvre les pixels, les matrices, le bruit, la lumière, les images réelles, OpenCV, les prétraitements, les zones d’intérêt, les contours, l’augmentation de données, la classification d’images, le transfer learning, la détection, la segmentation et le déploiement d’une mini API.
L’objectif est de construire un pipeline vision propre, capable de passer du prototype à une mini-application utilisable.
Le lecteur apprend aussi à éviter les pièges classiques : dataset trop propre, métriques trompeuses, modèle qui marche sur les images de test mais échoue avec les photos du monde réel.
Embeddings & Recherche sémantique : Construire un mini RAG solide
Ce volume explique comment construire un assistant capable de répondre à partir de documents.
On y découvre les embeddings, la recherche sémantique, le découpage des documents, les vecteurs, la similarité cosine, le top-k, les seuils de confiance, les vector stores comme FAISS ou Chroma, et la logique RAG : Retrieve, Augment, Answer.
L’objectif est de construire un “ChatGPT sur ses documents”, mais avec des sources, des limites et une règle claire : si l’information n’est pas dans le contexte, l’assistant ne doit pas inventer.
Ce volume insiste sur la fiabilité, les citations, l’évaluation et les erreurs fréquentes des assistants documentaires.
Fine-Tuning & LoRA : Personnaliser un modèle sans usine à gaz
Ce volume explique comment adapter un modèle à un style, un domaine ou un cas métier précis.
Le lecteur apprend la différence entre RAG, fine-tuning et LoRA, comment créer un dataset propre, comment éviter les données sensibles ou toxiques, comment entraîner légèrement un modèle, comment évaluer le résultat, comment comparer le modèle de base et le modèle adapté, et comment déployer avec versioning et rollback.
L’objectif n’est pas de faire du fine-tuning parce que c’est à la mode.
L’objectif est de comprendre quand cela a du sens, comment le faire proprement et comment éviter de casser le comportement du modèle.
Agents IA : Automatiser des tâches
Ce volume montre comment construire un agent IA qui ne se contente pas de répondre, mais qui peut agir avec des outils.
Le lecteur découvre la différence entre un chatbot et un agent, les tools, la mémoire, la planification, les workflows, les permissions, les validations, les guardrails, les logs, l’audit et les limites à ne pas dépasser.
L’objectif est de construire des agents contrôlables, capables de chercher, résumer, classer, proposer, préparer des actions, mais sans faire n’importe quoi.
Le livre insiste sur un point important : un agent doit être utile, mais aussi limité, surveillé et vérifiable.
MLOps pour débutants : Du Notebook à la Production
Ce volume explique comment passer d’un modèle qui marche dans un notebook à un mini-produit ML plus propre.
On y découvre la structure d’un projet ML, le versioning des données, du code et des modèles, la reproductibilité, les environnements, MLflow, les tests, FastAPI, Docker, le monitoring, les métriques, le drift, les logs, le rollback et la livraison d’un modèle.
L’objectif est de faire comprendre que le modèle n’est qu’une partie du travail.
En entreprise, il faut aussi savoir organiser, versionner, déployer, surveiller et maintenir.
Ce volume aide le lecteur à passer du prototype bricolé au projet plus professionnel.
À qui s’adresse cette collection ?
Cette collection s’adresse aux débutants complets, aux étudiants, aux autodidactes, aux développeurs, aux analystes, aux techniciens IT, aux personnes en reconversion et à tous ceux qui veulent comprendre l’intelligence artificielle par la pratique.
Elle est utile si vous voulez :
comprendre l’IA sans jargon inutile ;
apprendre le machine learning avec Python ;
construire des modèles de régression et classification ;
comprendre les réseaux de neurones ;
traiter du texte avec le NLP ;
faire de la vision par ordinateur ;
comprendre les embeddings et le RAG ;
personnaliser un modèle avec LoRA ;
créer des agents IA avec garde-fous ;
passer d’un notebook à un mini-produit déployable ;
développer des projets IA utiles pour un portfolio.
Ce que vous allez apprendre progressivement
À travers cette collection, vous allez apprendre à :
préparer des données correctement ;
choisir le bon type de modèle ;
entraîner un modèle sans tricher ;
évaluer avec les bonnes métriques ;
éviter le sur-apprentissage et la fuite de données ;
comprendre les réseaux de neurones ;
utiliser Scikit-learn, PyTorch, TensorFlow, OpenCV, FastAPI ou MLflow ;
traiter du texte réel ;
analyser des images ;
construire une recherche sémantique ;
créer un mini RAG fiable ;
personnaliser un modèle avec méthode ;
concevoir un agent IA contrôlable ;
déployer un modèle plus proprement ;
raisonner comme quelqu’un qui construit un outil IA, pas seulement comme quelqu’un qui lance un notebook.
L’esprit Aide en Informatique
Comme toujours avec Aide en Informatique, cette collection n’a pas été écrite pour impressionner les experts.
Elle a été pensée pour celles et ceux qui veulent apprendre simplement, sérieusement et progressivement.
Nous écrivons pour les débutants, les étudiants, les autodidactes, les personnes en reconversion, les développeurs curieux et tous ceux qui partent de zéro, de moins un, ou même de très loin.
Notre objectif n’est pas de faire de la théorie pour la théorie.
Notre objectif est d’aider le lecteur à comprendre, pratiquer, tester, se tromper, corriger et construire.
L’intelligence artificielle peut sembler compliquée parce qu’elle mélange données, statistiques, programmation, modèles, outils modernes et vocabulaire très à la mode.
Mais avec une progression claire, des analogies simples et des projets concrets, elle devient beaucoup plus accessible.
Si vous voulez apprendre l’IA sans vous perdre dans le blabla, comprendre les notions importantes et construire de vrais mini-projets pratiques, cette collection est faite pour vous.
cliquez ici pour acceder à la Collection — IA Sans Prise de Tête sur AMAZON
Collection : Les Maths Derrière L'IA (Série de 5 livres) sur AMAZON
Quelle est votre réaction?